天下赢家资讯看点:NLP到了“数据为王”的时代
很长一段时间以来,在过往AI的发展中数据的采集与标注行业没有过多地被关注,毕竟,与算法、算力这些高大上的东西相比,AI数据的生产总带着那么几分与AI技术的“科技感”截然不同的形象。
然而,随着AI的发展走向纵深,更多人发现这是一个误解,AI数据产业正在向着高专业化、高质量化的方向蓬勃发展。
根据2018年智研发布的《2019-2025年中国数据标注与审核行业市场专项分析研究及投资前景预测报告》,2018年该行业市场规模已达到52.55亿元,2020年市场规模有望突破百亿。有行业人士估计AI项目中会有10%的资金用于数据的采集和标记,2020年,数据标注行业最终市场规模将达到150亿。
而分享市场的,既有BAT、京东等互联网巨头,也有云测数据这种专注于高质量交付的专业化数据平台。
庞大的前景下,数据采集与标注也可以分NLP(自然语音处理)、CV(计算机视觉)等几个部分,随着数据需求量的增大、对数据质量要求的提高,其中的NLP越来越成为“硬骨头”,AI数据产业终将面临它带来的难题,也承袭这种难题下空出的市场空间。
AI的数据、算法和算力“轮流坐庄”,NLP到了“数据为王”的时代
芯片制程以及大规模并联计算技术的发展,使得算力快速提升后,AI能力的提升主要集中到了算法和数据上(算力提升当然还有价值,只是相对价值那么明显了,例如不可能对一个物联网终端设备有太多的算力设定要求)。
这方面,多年以来,人工智能技术都呈现“轮流坐庄”的螺旋提升关系:
算法突破后,可容纳的数据计算量往往变得很大,所以会迎来一波数据需求的高潮;而当AI数据通过某些方式达到一个新的程度时,原来的算法又“不够了”,需要提升。
2018年11月,Google AI团队推出划时代的BERT模型,在NLP业内引起巨大反响,认为是NLP领域里程碑式的进步,地位类似于更早期出现的Resnet相对于CV的价值。
以BERT为主的算法体系开始在AI领域大放异彩,从那时起,数据的重要性排在了NLP的首位。
加上两个方面的因素,这等于把NLP数据采集与标注推到了更有挑战的位置上。
一个因素,是NLP本身相对CV在AI数据方面的要求就更复杂。
CV是“感知型”AI,在数据方面有Ground Truth(近似理解为标准答案),例如在一个图片中,车、人、车道线等是什么就是什么,在采集和标注时很难出现“感知错误”(图片来源:云测数据)
而NLP是“认知”型AI,依赖人的理解不同产生不同的意义,表达出各种需要揣测的意图,Ground Truth是主观的。
例如,“这房间就是个烤箱”可能是说房间的布局不好,但更有可能说的是里边太热。人类语言更富魅力的“言有尽而意无穷”的特点,应用于AI时,需要被多方位、深度探索。
另一个因素,是AI数据的价值整体上由“饲料”到“奶粉”,对NLP而言这更有挑战。
大部分算法在拥有足够多常规标注数据的情况下,能够将识别准确率提升到95%,而商业化落地的需求现在显然不止于此,精细化、场景化、高质量的数据成为关键点,从95% 再提升到99% 甚至99.9%需要大量高质量的标注数据,它们成为制约模型和算法突破瓶颈的关键指标。
但是,正如云测数据总经理贾宇航所言,“图像采标有很强的规则性,按照规范化的指导文档工作即可,但NLP数据对应的是语言的丰富性,需要结合上下文等背景去理解和处理。”在高位提升这件事上,NLP数据更难。
例如,在订机票这个看似简单的AI对话场景中,想订票的人会有多种表达,“有去上海的航班么”,“要出差,帮我查下机票”,“查下航班,下周二出发去上海”……自然语言有无穷多的组合表现出这个意图,AI要“认得”它们,就需要大量高质量的数据的训练。
由此,我们再来理解商业机会。
数据采集与标注的公司有很多,从巨头的“副业”到AI数据专业化平台,总体而言主要玩家如图所示:
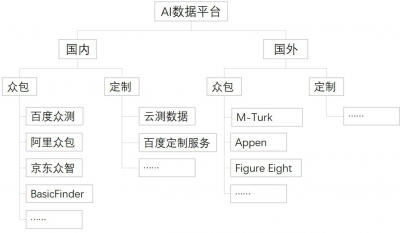 除此之外,更多中小玩家甚至几十人的草台班子数不胜数。在中国,目前全国从事数据标注业务的公司约有几百家,全职的数据标注从业者有约20万人,兼职数据标注从业者有约100万人。
易入门、难精通,而上述两大因素决定NLP数据面临巨大的挑战,做得好的就更少。
在数据“坐庄”NLP的大背景下,空出了大量的商业机会,而客观上的高要求阻却了大量低门槛入场的玩家,NLP数据相对于CV更像一个蓝海。
打破单纯“体力活”标签,NLP数据采集与标注从四个方面自我演进
有机会就总有人会进场,不久前,中国人工智能高峰论发布了中国人工智能科技服务商50强,既有商汤、旷视这种明星企业,也出现了榜单内唯一的AI数据服务商云测数据,这显示AI数据正在进入“主流圈”,在蓝海中尝试跑出独角兽企业。
当然,前提是平台能够解决好NLP数据的痛点问题。
事实上,CV的“感知”需求使得“体力活”可能就能够胜任大多数据生产工作(谁不认识一辆车、一个人呢),而“认知”的NLP数据要突围,只是“体力活”早已经不够。
至少目前来看,行业玩家在四个方面有所动作,或正在解决NLP数据痛点问题。
1、业务模式,用“定制化”迎合商业落地期的NLP
曾有媒体向Google工程师提起M-Turk的时候,他表示“我们不敢用Turk标注”,因为回收的数据良莠不齐。
众包模式(在公开平台发布任务,自由申领)是曾经的AI数据产业主流,拥有数据丰富性和多样性的优势,不过数据质量比较难以把控。在数据精细化要求的今天,很多需求方都转向了“定制化”(一对一,以项目制的方式完成交办的数据任务)服务模式。
例如,云测数据的“定制化”服务模式,跟的就是需求方复杂、精深而个性化的数据要求。具体到NLP,在数据采集上满足特定人物(老人、妇女、小孩)、特定场景(家居、办公、商业等)、不同方言的声音/文本数据采集;在数据标注上进行需求的对接、理解清楚场景化要求再分发尽量具体的规范指导(同样一句话在不同交流目的中可能需要标注不同的内容,例如“我没钱”在信贷服务中意味着潜在客户,在理财服务中则表达拒绝的态度)。
当然,众包模式也有它的优点,能够轻量化承载大量相对简单的数据需求,而场景化的定制模式则更专业,主要依靠自有员工和基地,像云测数据就在华东、华南、华北拥有自建标注基地,这种玩法显然更适合匹配客单价更高的场景化、定制化需求,NLP是典型。
2、管理流程,从“粗放制造”到“精益制造”
既然数据采集与标注很像是工厂的流水线,那么如果要提升数据的精准度,其实就如同“制造业”升级那样需要进行“粗放制造”到“精益制造”的转变,首要体现在管理流程的优化上。
无论是从平台接取任务的众包团队,还是直接对接需求方的定制化服务平台,至少,草台班子式的做法已经不适合NLP对数据的要求。
高精准度、高效率,都依赖管理流程的优化,以云测数据为例,具体做法包括这几个大方向:
标注、审核、抽检的层层把关:标注人员的结果交由另一批人进行审核,打回不合格的,最终再由质检进行抽检,大体如此,可能步骤更复杂;
人才类型的基础分类:文本、语音、图像标注人员不相互混用;
擅长场景的优先任务派发:在同等条件下,擅长对应场景的人优先派发给任务。
例会制度:如同精细化管理的制造业一样,早会、晚会、周会、月会,总结问题、提醒改进。
……
而无论如何,管理流程的事,说得再多,日常工作的落实才是最重要的。
3、职业技能,专业培训摆脱“低水平重复”
“不要门槛”意味着更低的价值,在人员个人能力上,NLP在逐渐抛弃那些“无门槛”入局的人,尤其是在特定的场景需求下。
例如,这是一个非常简单的NLP数据标注实例:
除此之外,更多中小玩家甚至几十人的草台班子数不胜数。在中国,目前全国从事数据标注业务的公司约有几百家,全职的数据标注从业者有约20万人,兼职数据标注从业者有约100万人。
易入门、难精通,而上述两大因素决定NLP数据面临巨大的挑战,做得好的就更少。
在数据“坐庄”NLP的大背景下,空出了大量的商业机会,而客观上的高要求阻却了大量低门槛入场的玩家,NLP数据相对于CV更像一个蓝海。
打破单纯“体力活”标签,NLP数据采集与标注从四个方面自我演进
有机会就总有人会进场,不久前,中国人工智能高峰论发布了中国人工智能科技服务商50强,既有商汤、旷视这种明星企业,也出现了榜单内唯一的AI数据服务商云测数据,这显示AI数据正在进入“主流圈”,在蓝海中尝试跑出独角兽企业。
当然,前提是平台能够解决好NLP数据的痛点问题。
事实上,CV的“感知”需求使得“体力活”可能就能够胜任大多数据生产工作(谁不认识一辆车、一个人呢),而“认知”的NLP数据要突围,只是“体力活”早已经不够。
至少目前来看,行业玩家在四个方面有所动作,或正在解决NLP数据痛点问题。
1、业务模式,用“定制化”迎合商业落地期的NLP
曾有媒体向Google工程师提起M-Turk的时候,他表示“我们不敢用Turk标注”,因为回收的数据良莠不齐。
众包模式(在公开平台发布任务,自由申领)是曾经的AI数据产业主流,拥有数据丰富性和多样性的优势,不过数据质量比较难以把控。在数据精细化要求的今天,很多需求方都转向了“定制化”(一对一,以项目制的方式完成交办的数据任务)服务模式。
例如,云测数据的“定制化”服务模式,跟的就是需求方复杂、精深而个性化的数据要求。具体到NLP,在数据采集上满足特定人物(老人、妇女、小孩)、特定场景(家居、办公、商业等)、不同方言的声音/文本数据采集;在数据标注上进行需求的对接、理解清楚场景化要求再分发尽量具体的规范指导(同样一句话在不同交流目的中可能需要标注不同的内容,例如“我没钱”在信贷服务中意味着潜在客户,在理财服务中则表达拒绝的态度)。
当然,众包模式也有它的优点,能够轻量化承载大量相对简单的数据需求,而场景化的定制模式则更专业,主要依靠自有员工和基地,像云测数据就在华东、华南、华北拥有自建标注基地,这种玩法显然更适合匹配客单价更高的场景化、定制化需求,NLP是典型。
2、管理流程,从“粗放制造”到“精益制造”
既然数据采集与标注很像是工厂的流水线,那么如果要提升数据的精准度,其实就如同“制造业”升级那样需要进行“粗放制造”到“精益制造”的转变,首要体现在管理流程的优化上。
无论是从平台接取任务的众包团队,还是直接对接需求方的定制化服务平台,至少,草台班子式的做法已经不适合NLP对数据的要求。
高精准度、高效率,都依赖管理流程的优化,以云测数据为例,具体做法包括这几个大方向:
标注、审核、抽检的层层把关:标注人员的结果交由另一批人进行审核,打回不合格的,最终再由质检进行抽检,大体如此,可能步骤更复杂;
人才类型的基础分类:文本、语音、图像标注人员不相互混用;
擅长场景的优先任务派发:在同等条件下,擅长对应场景的人优先派发给任务。
例会制度:如同精细化管理的制造业一样,早会、晚会、周会、月会,总结问题、提醒改进。
……
而无论如何,管理流程的事,说得再多,日常工作的落实才是最重要的。
3、职业技能,专业培训摆脱“低水平重复”
“不要门槛”意味着更低的价值,在人员个人能力上,NLP在逐渐抛弃那些“无门槛”入局的人,尤其是在特定的场景需求下。
例如,这是一个非常简单的NLP数据标注实例:
 它的需求可能只有初中语文即可。但是,NLP的数据需求早已超过这样的标注太多。
例如,客服询问用户是否购买此商品时,“我要和家人商量一下”、“我会考虑”、“我现在不方便,你一会儿再打过来”,标注人员得准确标注出暂不购买,暂不考虑,拒绝购买或者兴趣较大等多种意图。
一方面,这依赖于平台进行的场景深挖,这也是为什么云测数据智能客服单个场景的意图标注就分为10-20个大类、上百个子类,根据业务需求可能还会有进一步的标注细分,如此数据标注可以更细化、直达需求。
另一方面,这绕不开人员能力的持续培训,把“干体力”的标注工人转化成懂一些专业的业务人员,典型的如云测数据在金融服务领域通过几个月的专业培训,培养出销售人员视角去揣测用户话语中的意图。
举例来看,在客服沟通中,用户回馈“我在开车”这短短的一个语料数据,可能需要标记出“有车一族”、“司机”、“没有明显拒绝”、“可能有兴趣”等多个标注给NLP算法,按云测数据自己的说法,其培训达到的目标,是让标注员工达到成为专业员工的水准。
显然,在NLP标注数据的初期阶段将各大金融机构的AI客服机器人训练到大致相当的初级认知智能水平后,再进行提升、提高销售转化或者服务满意度,都需要质量更高、针对特定需求更强的NLP标注数据。
值得一提的是,在NLP领域不是所有标注都能通过人员培训来解决,医疗、法律等过于专业的领域可能还是依赖专家标注(邀请医生、律师等参与标注),那是一个更复杂的故事了。
4、工具使用,持续加码“便捷化”
工欲善其事必先利其器,NLP的标注虽然不像CV有很多空间维度的数据需求,但工具提升便捷度进而提升标准效率和准确性的价值仍然不可小觑。
这方面,巨头的脚步更早,在国外,Google Fluid Annotation一度是NLP标注“最好使”的工具,国内,大厂和专业平台的工具也被广泛使用,云测数据在工具上的创新优势很明显。
总体而言,标注工具适合自己的才是最好的。这种根据定制化需求开发贴合实际需要的数据工具对场景化数据的生产,发挥着重要作用。
无论如何,持续加码“便捷化”,是一个不会停止的过程。
NLP数据产业的机会,将会是谁坐庄?
在AI领域,虽然有大厂走在前列,但市场并没有被巨头垄断,中型AI平台也常常崭露头角成为主角。以AI数据服务领域为例,像云测数据这种专注于企业服务的第三方独立平台,以客户为中心的企业基因,一直贯穿在数据交付的始终。
一个典型的表现是,高精确度的NLP数据需要以企业服务的心态与客户仔细对接需求,例如,用户需求的场景是什么,如果是订票,AI问答应该主要导向订票,对应的NLP数据也要往这个方向去标注。
这一过程中需要数据服务人员对需求进行拆解、预判甚至提前给出建议,与客户反复沟通确认达成一致后,才能真正地去作业。大厂偏重于技术架构、前沿技术开发、云服务器中心大规模并发能力等建设,很难俯下身好好完成这件事,这时候,AI数据专业化平台更有优势。
此外,影响竞争格局走向的还有数据服务的安全性。
在数据采集与标注行业,复制一份数据在技术上非常简单,也能节省大量的人力和运营成本,但给客户带来的损失却不小(尤其是被竞争对手拿到),保证数据隐私性和安全性,在AI激烈的竞争环境下几乎成为某些客户的首要决策标准。
总而言之,高专业度、高精准度、高效率、强安全才能赢得AI数据客户尤其是NLP数据客户的选择,不论巨头还是AI数据专业化平台在行业爆发式增长的关口都在努力,落实和推进了诸多动作。NLP数据产业正处在蓝海,一个不会由巨头坐庄的蓝海。
(客户宣传稿件,图文均由客户提供,仅供参考)
它的需求可能只有初中语文即可。但是,NLP的数据需求早已超过这样的标注太多。
例如,客服询问用户是否购买此商品时,“我要和家人商量一下”、“我会考虑”、“我现在不方便,你一会儿再打过来”,标注人员得准确标注出暂不购买,暂不考虑,拒绝购买或者兴趣较大等多种意图。
一方面,这依赖于平台进行的场景深挖,这也是为什么云测数据智能客服单个场景的意图标注就分为10-20个大类、上百个子类,根据业务需求可能还会有进一步的标注细分,如此数据标注可以更细化、直达需求。
另一方面,这绕不开人员能力的持续培训,把“干体力”的标注工人转化成懂一些专业的业务人员,典型的如云测数据在金融服务领域通过几个月的专业培训,培养出销售人员视角去揣测用户话语中的意图。
举例来看,在客服沟通中,用户回馈“我在开车”这短短的一个语料数据,可能需要标记出“有车一族”、“司机”、“没有明显拒绝”、“可能有兴趣”等多个标注给NLP算法,按云测数据自己的说法,其培训达到的目标,是让标注员工达到成为专业员工的水准。
显然,在NLP标注数据的初期阶段将各大金融机构的AI客服机器人训练到大致相当的初级认知智能水平后,再进行提升、提高销售转化或者服务满意度,都需要质量更高、针对特定需求更强的NLP标注数据。
值得一提的是,在NLP领域不是所有标注都能通过人员培训来解决,医疗、法律等过于专业的领域可能还是依赖专家标注(邀请医生、律师等参与标注),那是一个更复杂的故事了。
4、工具使用,持续加码“便捷化”
工欲善其事必先利其器,NLP的标注虽然不像CV有很多空间维度的数据需求,但工具提升便捷度进而提升标准效率和准确性的价值仍然不可小觑。
这方面,巨头的脚步更早,在国外,Google Fluid Annotation一度是NLP标注“最好使”的工具,国内,大厂和专业平台的工具也被广泛使用,云测数据在工具上的创新优势很明显。
总体而言,标注工具适合自己的才是最好的。这种根据定制化需求开发贴合实际需要的数据工具对场景化数据的生产,发挥着重要作用。
无论如何,持续加码“便捷化”,是一个不会停止的过程。
NLP数据产业的机会,将会是谁坐庄?
在AI领域,虽然有大厂走在前列,但市场并没有被巨头垄断,中型AI平台也常常崭露头角成为主角。以AI数据服务领域为例,像云测数据这种专注于企业服务的第三方独立平台,以客户为中心的企业基因,一直贯穿在数据交付的始终。
一个典型的表现是,高精确度的NLP数据需要以企业服务的心态与客户仔细对接需求,例如,用户需求的场景是什么,如果是订票,AI问答应该主要导向订票,对应的NLP数据也要往这个方向去标注。
这一过程中需要数据服务人员对需求进行拆解、预判甚至提前给出建议,与客户反复沟通确认达成一致后,才能真正地去作业。大厂偏重于技术架构、前沿技术开发、云服务器中心大规模并发能力等建设,很难俯下身好好完成这件事,这时候,AI数据专业化平台更有优势。
此外,影响竞争格局走向的还有数据服务的安全性。
在数据采集与标注行业,复制一份数据在技术上非常简单,也能节省大量的人力和运营成本,但给客户带来的损失却不小(尤其是被竞争对手拿到),保证数据隐私性和安全性,在AI激烈的竞争环境下几乎成为某些客户的首要决策标准。
总而言之,高专业度、高精准度、高效率、强安全才能赢得AI数据客户尤其是NLP数据客户的选择,不论巨头还是AI数据专业化平台在行业爆发式增长的关口都在努力,落实和推进了诸多动作。NLP数据产业正处在蓝海,一个不会由巨头坐庄的蓝海。
(客户宣传稿件,图文均由客户提供,仅供参考)
除此之外,更多中小玩家甚至几十人的草台班子数不胜数。在中国,目前全国从事数据标注业务的公司约有几百家,全职的数据标注从业者有约20万人,兼职数据标注从业者有约100万人。
易入门、难精通,而上述两大因素决定NLP数据面临巨大的挑战,做得好的就更少。
在数据“坐庄”NLP的大背景下,空出了大量的商业机会,而客观上的高要求阻却了大量低门槛入场的玩家,NLP数据相对于CV更像一个蓝海。
打破单纯“体力活”标签,NLP数据采集与标注从四个方面自我演进
有机会就总有人会进场,不久前,中国人工智能高峰论发布了中国人工智能科技服务商50强,既有商汤、旷视这种明星企业,也出现了榜单内唯一的AI数据服务商云测数据,这显示AI数据正在进入“主流圈”,在蓝海中尝试跑出独角兽企业。
当然,前提是平台能够解决好NLP数据的痛点问题。
事实上,CV的“感知”需求使得“体力活”可能就能够胜任大多数据生产工作(谁不认识一辆车、一个人呢),而“认知”的NLP数据要突围,只是“体力活”早已经不够。
至少目前来看,行业玩家在四个方面有所动作,或正在解决NLP数据痛点问题。
1、业务模式,用“定制化”迎合商业落地期的NLP
曾有媒体向Google工程师提起M-Turk的时候,他表示“我们不敢用Turk标注”,因为回收的数据良莠不齐。
众包模式(在公开平台发布任务,自由申领)是曾经的AI数据产业主流,拥有数据丰富性和多样性的优势,不过数据质量比较难以把控。在数据精细化要求的今天,很多需求方都转向了“定制化”(一对一,以项目制的方式完成交办的数据任务)服务模式。
例如,云测数据的“定制化”服务模式,跟的就是需求方复杂、精深而个性化的数据要求。具体到NLP,在数据采集上满足特定人物(老人、妇女、小孩)、特定场景(家居、办公、商业等)、不同方言的声音/文本数据采集;在数据标注上进行需求的对接、理解清楚场景化要求再分发尽量具体的规范指导(同样一句话在不同交流目的中可能需要标注不同的内容,例如“我没钱”在信贷服务中意味着潜在客户,在理财服务中则表达拒绝的态度)。
当然,众包模式也有它的优点,能够轻量化承载大量相对简单的数据需求,而场景化的定制模式则更专业,主要依靠自有员工和基地,像云测数据就在华东、华南、华北拥有自建标注基地,这种玩法显然更适合匹配客单价更高的场景化、定制化需求,NLP是典型。
2、管理流程,从“粗放制造”到“精益制造”
既然数据采集与标注很像是工厂的流水线,那么如果要提升数据的精准度,其实就如同“制造业”升级那样需要进行“粗放制造”到“精益制造”的转变,首要体现在管理流程的优化上。
无论是从平台接取任务的众包团队,还是直接对接需求方的定制化服务平台,至少,草台班子式的做法已经不适合NLP对数据的要求。
高精准度、高效率,都依赖管理流程的优化,以云测数据为例,具体做法包括这几个大方向:
标注、审核、抽检的层层把关:标注人员的结果交由另一批人进行审核,打回不合格的,最终再由质检进行抽检,大体如此,可能步骤更复杂;
人才类型的基础分类:文本、语音、图像标注人员不相互混用;
擅长场景的优先任务派发:在同等条件下,擅长对应场景的人优先派发给任务。
例会制度:如同精细化管理的制造业一样,早会、晚会、周会、月会,总结问题、提醒改进。
……
而无论如何,管理流程的事,说得再多,日常工作的落实才是最重要的。
3、职业技能,专业培训摆脱“低水平重复”
“不要门槛”意味着更低的价值,在人员个人能力上,NLP在逐渐抛弃那些“无门槛”入局的人,尤其是在特定的场景需求下。
例如,这是一个非常简单的NLP数据标注实例:
它的需求可能只有初中语文即可。但是,NLP的数据需求早已超过这样的标注太多。
例如,客服询问用户是否购买此商品时,“我要和家人商量一下”、“我会考虑”、“我现在不方便,你一会儿再打过来”,标注人员得准确标注出暂不购买,暂不考虑,拒绝购买或者兴趣较大等多种意图。
一方面,这依赖于平台进行的场景深挖,这也是为什么云测数据智能客服单个场景的意图标注就分为10-20个大类、上百个子类,根据业务需求可能还会有进一步的标注细分,如此数据标注可以更细化、直达需求。
另一方面,这绕不开人员能力的持续培训,把“干体力”的标注工人转化成懂一些专业的业务人员,典型的如云测数据在金融服务领域通过几个月的专业培训,培养出销售人员视角去揣测用户话语中的意图。
举例来看,在客服沟通中,用户回馈“我在开车”这短短的一个语料数据,可能需要标记出“有车一族”、“司机”、“没有明显拒绝”、“可能有兴趣”等多个标注给NLP算法,按云测数据自己的说法,其培训达到的目标,是让标注员工达到成为专业员工的水准。
显然,在NLP标注数据的初期阶段将各大金融机构的AI客服机器人训练到大致相当的初级认知智能水平后,再进行提升、提高销售转化或者服务满意度,都需要质量更高、针对特定需求更强的NLP标注数据。
值得一提的是,在NLP领域不是所有标注都能通过人员培训来解决,医疗、法律等过于专业的领域可能还是依赖专家标注(邀请医生、律师等参与标注),那是一个更复杂的故事了。
4、工具使用,持续加码“便捷化”
工欲善其事必先利其器,NLP的标注虽然不像CV有很多空间维度的数据需求,但工具提升便捷度进而提升标准效率和准确性的价值仍然不可小觑。
这方面,巨头的脚步更早,在国外,Google Fluid Annotation一度是NLP标注“最好使”的工具,国内,大厂和专业平台的工具也被广泛使用,云测数据在工具上的创新优势很明显。
总体而言,标注工具适合自己的才是最好的。这种根据定制化需求开发贴合实际需要的数据工具对场景化数据的生产,发挥着重要作用。
无论如何,持续加码“便捷化”,是一个不会停止的过程。
NLP数据产业的机会,将会是谁坐庄?
在AI领域,虽然有大厂走在前列,但市场并没有被巨头垄断,中型AI平台也常常崭露头角成为主角。以AI数据服务领域为例,像云测数据这种专注于企业服务的第三方独立平台,以客户为中心的企业基因,一直贯穿在数据交付的始终。
一个典型的表现是,高精确度的NLP数据需要以企业服务的心态与客户仔细对接需求,例如,用户需求的场景是什么,如果是订票,AI问答应该主要导向订票,对应的NLP数据也要往这个方向去标注。
这一过程中需要数据服务人员对需求进行拆解、预判甚至提前给出建议,与客户反复沟通确认达成一致后,才能真正地去作业。大厂偏重于技术架构、前沿技术开发、云服务器中心大规模并发能力等建设,很难俯下身好好完成这件事,这时候,AI数据专业化平台更有优势。
此外,影响竞争格局走向的还有数据服务的安全性。
在数据采集与标注行业,复制一份数据在技术上非常简单,也能节省大量的人力和运营成本,但给客户带来的损失却不小(尤其是被竞争对手拿到),保证数据隐私性和安全性,在AI激烈的竞争环境下几乎成为某些客户的首要决策标准。
总而言之,高专业度、高精准度、高效率、强安全才能赢得AI数据客户尤其是NLP数据客户的选择,不论巨头还是AI数据专业化平台在行业爆发式增长的关口都在努力,落实和推进了诸多动作。NLP数据产业正处在蓝海,一个不会由巨头坐庄的蓝海。
(客户宣传稿件,图文均由客户提供,仅供参考)
作者:佚名 责任编辑:刘洋
相关文章
热门活动

陈海平-牛来了,证券投资为啥赚的利润少?“锚定效应”悄悄在作怪?
2020-09-04

陈海平-虚假宣传
2020-07-31

陈海平老师-本周以来股市大涨 重要股东减持超80亿元
2020-09-04

收评:大盘阳包阴再现中阳创新高
2020-09-03
要求退款
2020-07-31
A股强势“反包”!一举攻下3400!接下来的中报行情如何布局?
2020-09-03
热门专题
陈海平老师-热点前瞻:超级闪充+特斯拉+风能+农业板块
2020-09-03
陈海平股票-盛趣游戏新品霸屏 世纪华通稳坐A股游戏头把交椅
2020-09-04

赚翻了,一个季度业绩超过大半年的高德红外
2020-08-31
星徽精密晋级8连板,而这只股票盘中最高涨将近800%!
2020-08-31
陈海平股票-正荣服务港交所上市:市值超50亿港元 欧宗荣为大股东
2020-09-03
陈海平股票-国家队出手 潜伏这些股等待补涨机会
2020-09-03
热门政策
陈海平老师-惠誉:予佳兆业集团拟发行高级无抵押美元票据“B”评级
2020-08-31
陈海平股票-一个消息传来,A股应声杀跌
2020-09-03
大牛市来临,三大板块的攻击力最刚劲最勇猛!
2020-08-31
大赚1354万!这家中国纺织百强作价2589万转让建立26年的制衣厂
2020-09-04
陈海平-七月板块涨幅高达36% 各路资金扫货“牛市旗手”券商股
2020-09-04

特斯拉结束六连涨,马斯克仍有望再获18亿股权收入
2020-08-10
热门视频
盛趣游戏新品霸屏 世纪华通稳坐A股游戏头把交椅
2020-08-31
陈海平-早晨平安:高层定调!大力发展工业互联网,更大释放消费潜力
2020-09-03
陈海平-赚翻了,一个季度业绩超过大半年的高德红外
2020-09-04
来分期 我今天中午借了10000没到账 资金被冻结 货款合同收款帐号被修改
2020-07-31
陈海平老师-盈利能力下行,造血功能不足,这家房企净负债率竟超200%!
2020-08-31
陈海平-天量!17000亿的跳水,说明了什么?
2020-08-31
热门资讯
美国股指期货小幅上涨 - 关注TSLA、DIS、CSCO
2020-11-30
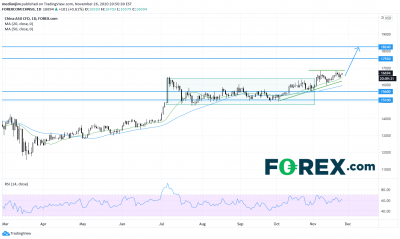
中国A50指数:等待上破信号
2020-11-30
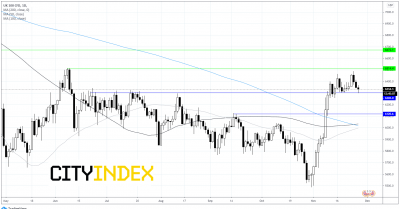
疫苗疑虑挫伤人气,FTSE关注6325支撑的得失
2020-11-30
陈海平-两大主营产品发展不一,明源云IPO区域销售合作伙伴靠得住吗?
2020-08-31
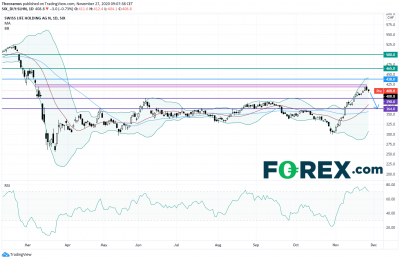
欧洲股市周四继续涨跌互见
2020-11-30
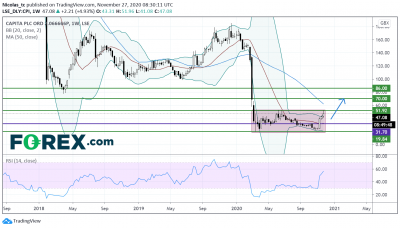
Capita股价面临重大阻力
2020-11-30